调度器分支之RTG |
您所在的位置:网站首页 › thread group › 调度器分支之RTG |
调度器分支之RTG
|
一、引言
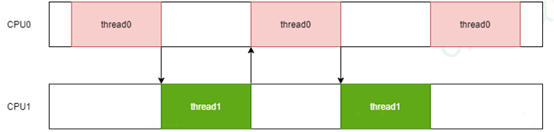
网上关于RTG内容很少,本文以作者个人的理解为主,难免存在偏差与瑕疵,欢迎指正。本文以codeaurora的https://source.codeaurora.cn/quic/la/kernel/msm-4.14/代码及msm-5.4进行分析。 在详细介绍rtg之前,需要了解一下rtg的背景。Rtg叫着related thread group.顾名思义“相关线程组”。这个怎么理解呢? 我们设想一种场景,有两个跑分线程,一个叫thread0,另外一个叫thread1. 其中thread0执行一段时间之后唤醒thread1执行,然后自己睡眠。同样的thread1运行一段时间之后唤醒thread0执行,自己睡眠,如此反复。假如thread0跟thread1分别运行在不同的CPU上,示意图如下:
又假设thread0跟thread1每次运行时长都是一样。这时候CPU0跟CPU1的使用率都是50%,一般来讲达不到 80%的CPU使用率这样的DCVS提频条件。 如果假如thread0跟thread1都运行在同一个CPU上呢,如下示意图
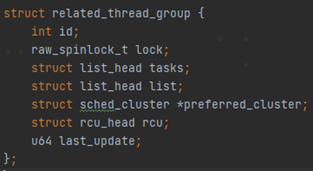
那么CPU0始终处于100%的使用率,CPU频率会一直上提,一直到最高。 同样的测试用例,就因为调度时任务运行在不同的CPU上,导致最终的结果完全不一样。与这种情况比较类似的就是android显示里面的应用主线程及render线程。 上面只是举了一个简单的例子,来说明rtg出现的背景,即系统的线程不是孤立的,它们之间存在各种依赖关系。那从不管是调度的角度讲、还是从DCVS的角度,都不能忽视这种存在。而恰恰当前的CFS调度里面忽略了这种关联性,因此RTG横空出世。 由于rtg的发展有一些历史,直接看最新的代码会比较费解,所以我们从codeaurora的msm-4.14 版本(https://source.codeaurora.cn/quic/la/kernel/msm-4.14/)的代码开始了解一下rtg的真面目。 二、RTG之选核优化先看一下这个结构体的定义
其中id为每一个related_thread_group的唯一识别号,从1开始,系统默认的rtg组的DEFAULT_CGROUP_COLOC_ID就是1。 tasks为一个链表,里面都是属于该组的进程,通过add_task_to_group及remove_task_from_group来进行添加或者删除。 list为group组所在的链表,其中active_related_thread_groups为一个全局链表,里面都是所有不同id的related_thread_group。一个新的group创建的时候会被加入到这个链表。 preferred_cluster是一个struct sched_cluster类型的结构体指针,指整个rtg组的线程调度时优先选择推荐的cluster(CPU簇)。这里对这个结构体不展开描述,不影响我们对于rtg的理解。 last_update是记录_set_preferred_cluster中每次preferred_cluster更新的时间戳。用来避免频繁的更新preferred_cluster。 上面介绍了几个关键的字段,也为此实现了相关的工具函数。
系统中默认创建了一个id为DEFAULT_CGROUP_COLOC_ID的组。并且在stune cgroup的top-app组里面默认打开。
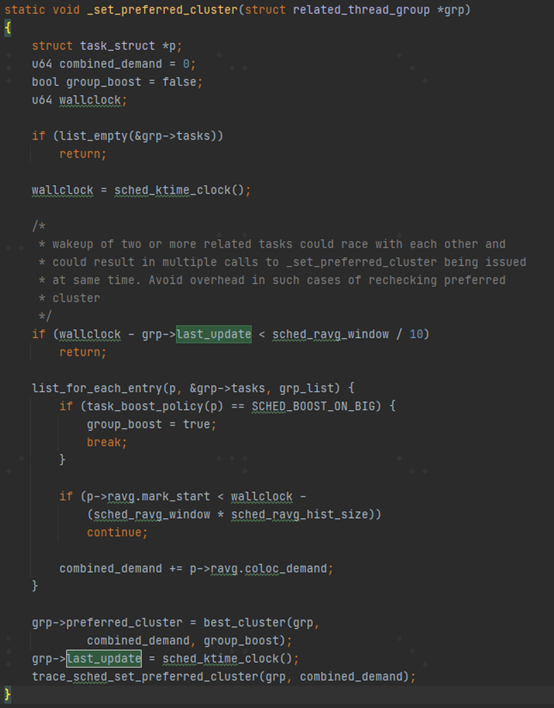
那么top-app里面的所有线程的这个属性都为1了。具体见cgroup的实现walt_schedgp_attach函数。这样相关的线程都被sync_cgroup_colocation 加入到default的RTG组里面了。至此我们知道android系统的top-app组,即前台应用的相关线程被加入到一个id为DEFAULT_CGROUP_COLOC_ID的related thread group组里面。这里需要注意一点是schedtune.colocate不支持动态更新,原因是在于只有在做cgroup切换的时候,才把相关的任务加到rtg组里面,后面也仅仅只有新创建的new task被wake_up_new_task中调用add_new_task_to_grp被加入到DEFAULT_CGROUP_COLOC_ID组。即使支持动态开关,也只有下一次应用切换的时候才会生效。因为干脆不支持动态开关。 至此related_thread_group结构体里面的主要字段都做了基本的介绍。下面从preferred_cluster字段开始,沿着这条线继续介绍代码。我们看到当一个线程加入到这个组里面的时候,函数add_task_to_group会调用_set_preferred_cluster函数。下面我们对这个函数详细的介绍一下。
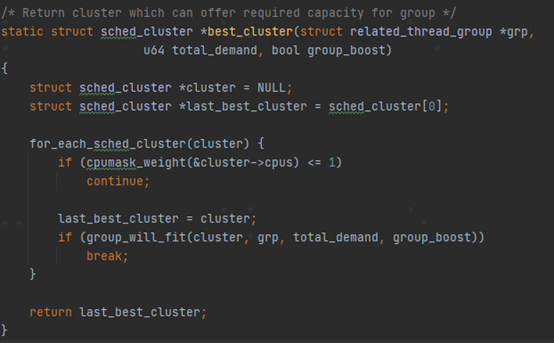
首先可以看到last_update字段的用处了,防止_set_preferred_cluster被频繁的调用。这个约束时间最短为窗口周期的1/10; 这个函数继续看group组里面的是否有线程被设置了SCHED_BOOST_ON_BIG属性(per-task的属性,辅助进行任务调度选核的策略)这样的任务摆核策略,如果是的话,就直接将整个组boost到大核上。然后通过遍历group里面的所有tasks,计算累计负载。然后通过best_cluster选择一个preferred_cluster。
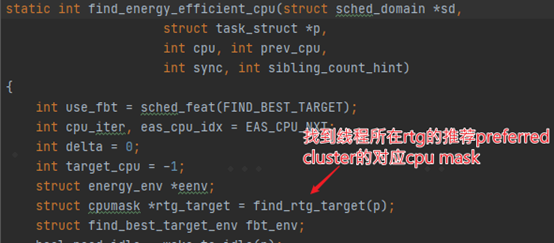
best_cluster的代码比较简单,输入参数为上面提到的累计负载。通过sched_group_upmigrate及sched_group_downmigrate来判断选择一个合适的CPU簇。注意这个代码的注释,返回一个可以满足group所需算力的CPU簇。 sched_group_upmigrate和sched_group_downmigrate这两个参数是不是跟sched_upmigrate和sched_downmigrate很像?只不过sched_upmigrate跟sched_downmigrate是用来判断单个任务是否需要运行在大核的条件。 这里就引出了rtg的第一个作用,即RTG希望将group组里面的关联线程都放在同一个CPU簇上。为什么需要这么做呢?在文章开头的地方讲到了,related_thread_group里面都是一些存在相关联系的线程(虽然当前top-app组稍显粗暴,而且不够全面,没有考虑到锁、binder通信等等各种情况),它们之间大概率会存在数据的共享。而一个cluster之间是存在共享cache的,因此可以合理的利用这些cache来提升性能降低功耗。还有一个原因就是后面要讲到的RTG的第二个功能。 在CFS的find_energy_efficient_cpu里面可以看到。在后续的task的选核中,针对rtg里面的线程,进行选核上的一些优先。具体代码不详细展开描述。
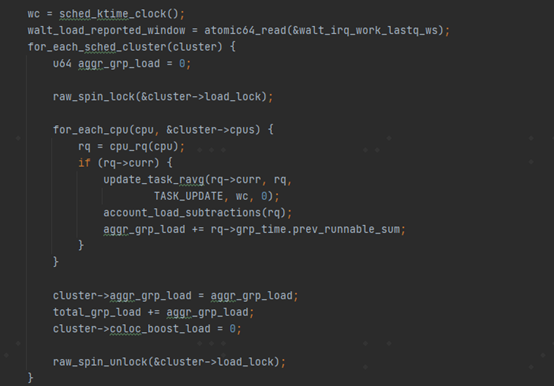
在后续的kernel版本升级及代码演进中,又进行了一些功能的调整,比如在5.4内核上,引入skip_min来替代perferredcluster,并通过sched_min_task_util_for_colocation来过滤掉负载较低的任务,当任务负载低于sched_min_task_util_for_colocation时,其选核时的优先调度大核任然可以持续维持sched_task_unfilter_period的时间(这个名字也很有趣,不过滤的时间周期,迟滞一段时间)。整体功能并没有发生大的变化。 三、RTG之聚合调频 RTG的第二个功能是任务负载的聚合调频(Frequency aggregation)。回到文章开头讲到跑分场景,让thread0跟 thread1在两种场景下(运行在两个CPU vs 运行在同一个CPU上)的效果一致。需要一种策略来进行DCVS调频的优化。RTG的第二个功能也就是这么做的。 这段代码在walt_irq_work里面,我们看一下它是怎么实现的。
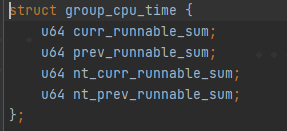
其中aggr_grp_load+= rq->grp_time.prev_runnable_sum用于累加group在每一个cluster上的负载,并放到cluster->aggr_grp_load = aggr_grp_load里面。那么rq->grp_time.prev_runnable_sum是如何统计出来的呢? 在每一个rq里面都有一个struct group_cpu_timegrp_time的字段。
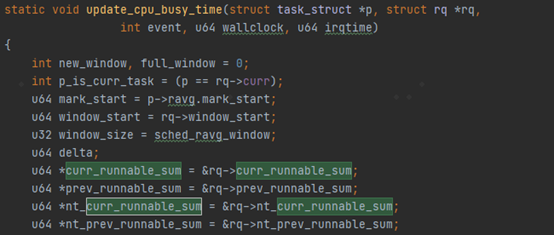
其中curr_runnable_sum跟prev_runable_sum是用来统计当前窗口跟前一个窗口的任务。nt_curr_runnable_sum跟nt_prev_runnable_sum中的nt指new task,是针对新创建线程的一种单独统计。那么哪些task是new task呢?简单粗暴,p->ravg.active_windows < SCHED_NEW_TASK_WINDOWS; active_windos 少于SCHED_NEW_TASK_WINDOWS(5)的任务即为new task。 下面从update_cpu_busy_time这个函数开始,这个函数是用来计算更新每一个任务的负载的。
除了rq->grp_time里面有这四个变量之外,在rq里面也存在这4个同名的变量。那么为什么会同时存在这4个变量呢?
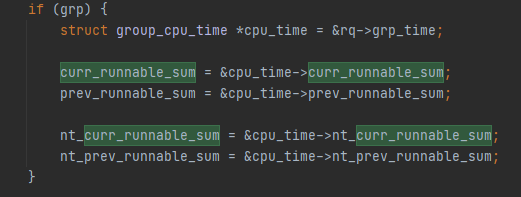
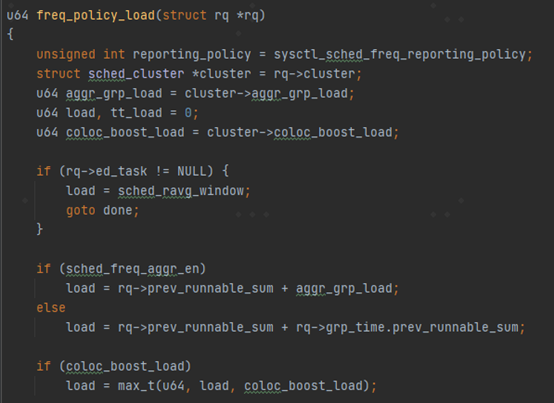
当线程p->grp不为空,即p属于一个related_thread_group里面的一个线程。那么curr_runnable_sum, prev_runnable_sum, nt_curr_runnable_sum,nt_prev_runnable_sum这4个指针就不再指向rq里面的相应字段了,而是指向了rq->grp_time里面的字段。 这说明什么呢?说明walt针对grp组相关线程的负载做了单独的统计,并没有直接累计到rq里面去。为什么需要单独统计呢?这就是为了方便在做负载聚合调频的时候能够快速的进行计算。 对于rq->grp_time的具体操作除了上面的update_cpu_busy_time,还有fixup_busy_time做任务迁核的修正,transfer_busy_time用于任务加入或者退出某个group时候的修正。rollover_cpu_window用于在window窗口周期到期的时候的一些数据处理。 最后我们看一下任务负载聚合的地方。在freq_policy_load里面。这个函数是用来给schedutil governor查询负载的时候用的。
当sched_freq_aggr_en为true的时候,一个rq上的负载等于其本身负载加上cluster->coloc_boost_load 也就是group在cluster上累计的负载。 当sched_freq_aggr_en为false的时候,负载就等于rq->prev_runnable_sum加上这个rq上rtg类型的线程的负载。这也就是我们通常意义上CPU的任务累计负载。 这里面的sched_freq_aggr_en是一个全局变量。具体是在kernel/sched/boost.c里面进行操作的。sched_boost里面支持多种boost的设置。
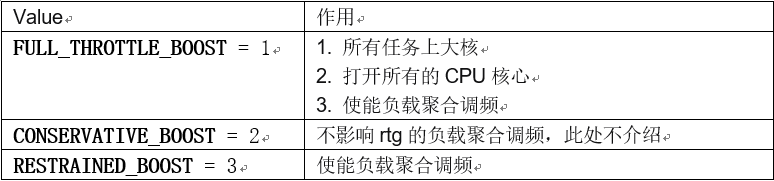
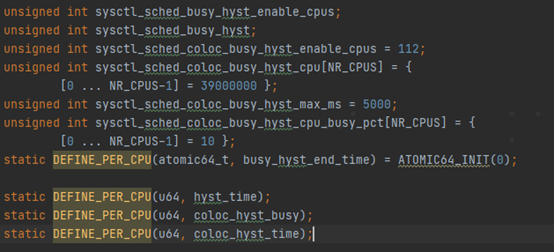
由于现在将top-app组里面的所有线程都加入到默认的related_thread_group里面的方式过于简单粗暴,所以在频率的聚合上进行了一些限制,只有在sched_boost设置为FULL_THROTTLE_BOOST或者RESTRAINED_BOOST的时候才开启负载聚合调频。这里面再次遵循一种设计原则,scheduler/DCVS提供机制,上层业务在合适的地方合理的利用这些机制,机制跟业务场景需求的合理组合搭配。当然当前基于top-app的线程做负载聚合是不够理想,以android系统的system server为例,它是一个系统服务,当他在处理来至于top-app线程的binder请求的时候,应该动态将其也归为top-app组,当处理完成后,需要将其恢复到原来的组里面。 四、RTG之Busy HysteresisRTG在新的内核版本上新引入的第三个功能叫着Busy Hysteresis,也是基于RTG的colocation这个功能,在后面的内核版本里面引入的。这时候perferredcluster已经被调整为skip_min。Hysteresis指迟滞,意思就是CPUbusy会持续迟滞一段时间。这个迟滞具体是指什么意思呢?且听慢慢道来。涉及的变量如下
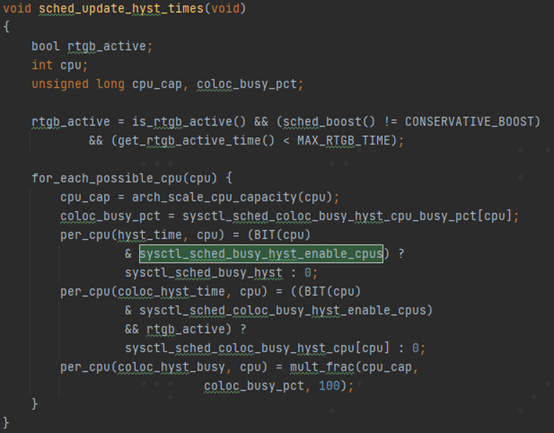
沿着函数sched_update_hyst_times可以大概了解一下这几个变量的含义。
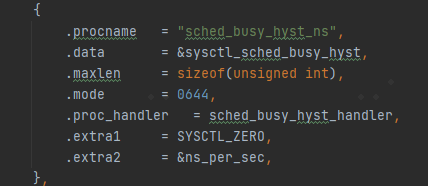
其中sysctl_sched_busy_hyst_enable_cpus是一个bitmap,每一个bit用来表示相应的cpu是否打开了busy_hyst功能。 sysctl_sched_busy_hyst名字比较费解。不过如果看sysctl接口的定义就比较一目了然。
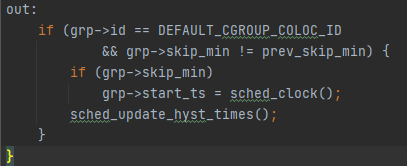
名字叫sched_busy_hyst_ns,是一个迟滞时间,单位为ns。 per_cpu(coloc_hyst_time, cpu) 这个per-cpu的赋值比较有意思,除了sysctl_sched_coloc_busy_hyst_cpu这个时间之外(默认定义为39ms),还有一个rtgb_active, rtgb_active最后又是跟related_thread_group的skin_min有关。 coloc_hyst_busy是根据百分比以及cpu的capacity换算过来的一个阈值。后面会具体在update_busy_hyst_end_time中被用到。 函数sched_update_hyst_times被_set_preferred_cluster调用,当skin_min发生变化的时候会更新相关的hyst的信息(如下图)。
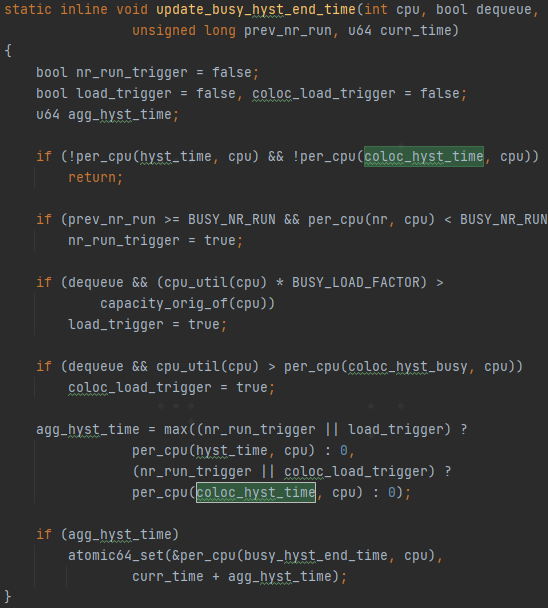
另外还有一个函数update_busy_hyst_end_time,被用来更新hyst end time,也就是迟滞的结束时间点。
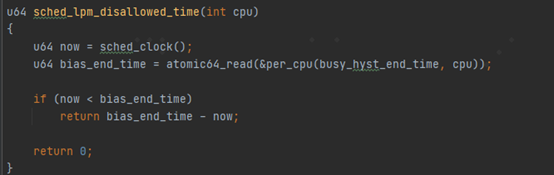
当dequeue为true,也就是cpu上任务数量减少的时候,并且cpu的负载大于coloc_hyst_busy(上面讲过了,基于CPU算力以及一个预制的百分比算出来的一个阈值)。这个busy_hyst_end_time的变量,我们后面会发现在sched_lpm_disallowed_time函数中被使用。
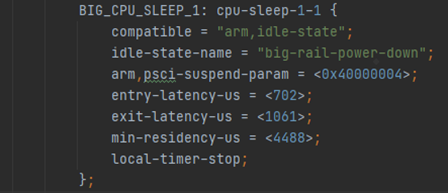
针对后面的代码不一一详细解释了,跟平台的LPM(low power mode)有关。 针对busyHysteresis做一个功能上的总结吧,通过预制的每一个cpu的capactity的阈值,当CPU的负载大于这个阈值的时候,会迟滞一定的时间,不让CPU进入LPM模式。那么为什么这么做呢? 具体要看LPM(Low Power Mode)了,挑选LPM的一段内核dts描述来解释这个问题(https://source.codeaurora.cn/quic/la/kernel/msm-5.4/tree/arch/arm64/boot/dts/qcom/sdm845.dtsi?h=LA.AU.0.2.0.r4.1#n412)。
其中entry-latency-us跟exit-latency-us分别描述了CPU进入跟退出这个层级(LPM分为多个等级,层级越高越省电,但是相应的进入跟退出的耗时越长。具体可以参考ARM官方文档)的LPM模式的时延。可以看到要从这一级的LPM模式退出,需要1061微秒的时间。随着手机刷新率越来越高,每一帧的处理时间越来越短,此外音频等一类业务对于时延要求非常高。这个LPM的退出时间从android systrace上可以很直观的观察到这种延迟。
粉色的代表CPU的C-state状态,也就是LPM状态。绿色的是一个unity线程的运行片段。在这两者之间并不是连贯的,有一段空白区间。这就是一个任务被调度到一个idle的CPU上所出现的情况,CPU退出LPM状态需要耗时。所以有时候prefer idle的调度选核策略也并不是最优的,需要看具体的情况而定。 另外还有一点,就是进入跟退出LPM都是需要耗费额外的功耗的,也正是因为如 此,上面的dtsi里有一个min-residency-us(上图中的示例为4488微秒),表示要获得功耗收益需要在此LPM状态下需要维持的最短时间。但是当一个CPU的负载较重的时候,即使可以短暂的进入LPM模式,大概率也会很快因为有任务需要运行而退出。所以此种情况下因为无法维持min-residency-us的功耗收益的最短时间要求,基本是不会获得功耗收益的,反而会因为频繁的进入退出LPM状态,相比维持在C0的WFI状态耗费更多的功耗。 本文大体讲了RTG功能的背景及作用。并没有对具体的代码片段展开详细的讲解,这部分留给读者自行完成,本文只起到一个引导与总结的作用。 参考文章: 1. codeaurora代码,https://source.codeaurora.cn/quic/la/kernel 2. ARM 官方文档,https://developer.arm.com/documentation
|


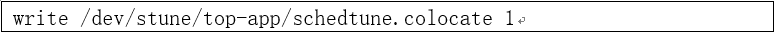


【本文地址】
今日新闻 |
推荐新闻 |